Format and Parsing
In this chapter, we describe the settings to correctly parse the format of the historical data file.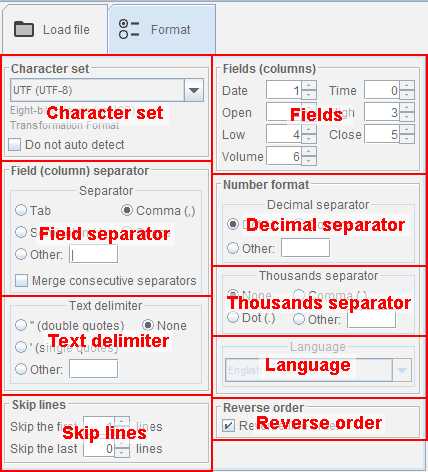
Introduction
In order to correctly parse the historical file, many non-trivial aspects must be taken into account. We suggest you read this chapter even if the auto-detect feature works like a charm for your data, because here you can develop the required sensibility in order to evaluate the correctness of the parsing.The Character Set
Character Set and Character Encoding
You don't need to know the theory behind character set and character encoding, or the difference between the two concepts. All you need to know is that you must select the right one, so that the file appears intelligible. If the wrong character set / encoding is selected, the file results in being gibberish, with 'strange' characters.The Character Set Combobox
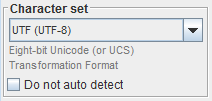 You select the character set / encoding through the combobox:
You select the character set / encoding through the combobox:
Character setA brief description of the character encoding is put in the label below the combobox.
What to Check For
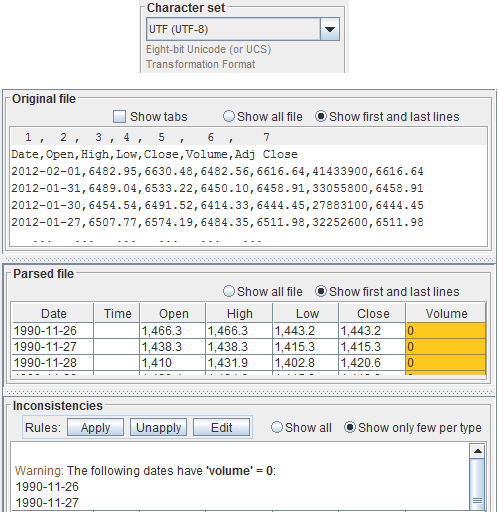
Upon selecting a character set, look at theOriginal file pane.
If you can read the file, you selected a suitable character set; if you can't, try another one.
Only the data count:
Date / time Open High Low Close VolumeThe header or other descriptive lines present in the file will be dismissed. So focus on data, without bothering much for the writings. With the wrong setting, all parsing results in errors, clearly visible everywhere, e.g. in spinners, in the parsed file and inconsistencies panes.
Which Character Set / Encoding to Try
Nowadays, the only character encoding used should be theUTF-8That is the first one to try. If it doesn't work, for western languages start trying, in the order:
- windows-1252 - US-ASCII - ISO-8859-1In all the other cases try selecting those whose name might be the right ones based on the country. For instance, if you downloaded data from a Japanese provider, try one of the
Japanese encoding.
Examples
Correct Character Set / Encoding
Wrong Character Set / Encoding
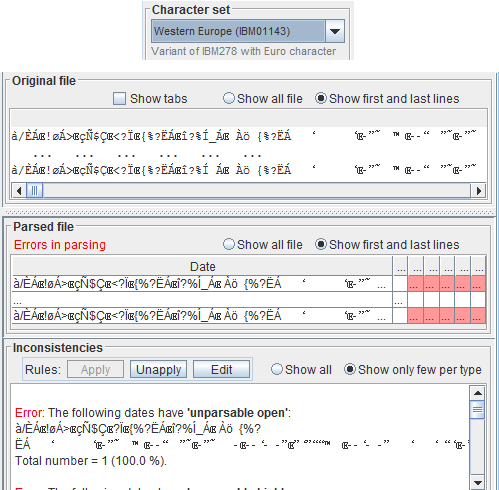
Wrong Character Set / Encoding
The Do not auto detect Checkbox
 If the auto detect feature doesn't select the right set, manually select the right one and then check the checkbox
If the auto detect feature doesn't select the right set, manually select the right one and then check the checkbox
Do not auto detectThis way, it will not be overridden each time you run the auto-detect routine.
Field Separator
Definitions
Each line of the historical file constitutes one entry and contains data such as:Date / time Open High Low Close VolumeEach of these data represents a field. Being on the same line, they must be separated by a specific character, so that it is clear where fields begin and end. Such specific character is the field separator. As fields are usually tabled in columns, the field separator is also known as column separator. Fields separators delimit columns data. Indeed, the
Parsed file pane shows fields in columns, where each column represents a field.
Pinpointing the Field Separator
The target of this paragraph is to pinpoint the field separator. When the field separator is selected properly, you will see each field in a different column in theParsed file pane.
So, upon selecting a field separator, always check the Parsed file table.
If the separator is the right one, each field will occupy one column.
While if it is a wrong separator, many kinds of errors can happen, like multiple fields being placed in the same column,
or one field being split into two parts with each part being placed in a different column.
Other errors likely will appear, as explained later on, but for now focus on the separation of the fields in the table.
Look at the Header First
Arguably the easiest way to identify the field separator is to look at the header, i.e. usually the first and only line reporting the column order, like:Date;Open;High;Low;Close;VolumeThe field separator for this line is the semicolon (;) and it is usually the same adopted for the rest of the file. Looking at lines with numbers may be more confusing, because, in some formatting, numbers can have commas and dots, like
1,234.56Separating them with semicolons:
2,120.36;2,182.30;2,100.59;2,164.44the semicolon is not readily apparent as separator.
Don't Look Only at the Header
Nonetheless, it can happen that the separator for the header is not the same as the one used for the other lines. The important lines are those containing data, not the header. So always look also at lines with data.Selecting the Field Separator
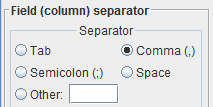 You select the field separator through the dedicated radio buttons.
Almost always the field separator is one of the following character:
You select the field separator through the dedicated radio buttons.
Almost always the field separator is one of the following character:
- Comma (,)
- Semicolon (;)
- Tab
- Space
Comma
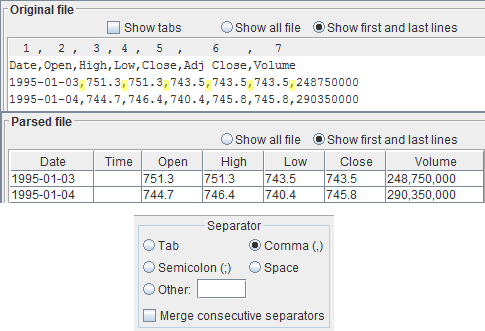 If your file looks like the one in the example, then the separator is the comma (','). Select the radio button
If your file looks like the one in the example, then the separator is the comma (','). Select the radio button
Comma (,)
Semicolon
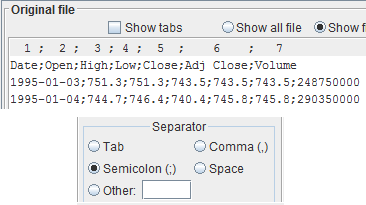 If your file looks like the one in the example, then the separator is the semicolon (';'). Select the radio button
If your file looks like the one in the example, then the separator is the semicolon (';'). Select the radio button
Semicolon (;)
Tab
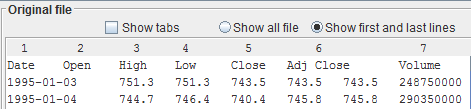 Tabs are not visible. A file whose field separator is a tab might look like the one in the example.
A first hint that the tab is the separator comes from the fact that the space between the fields varies within the same line:
can be narrower for a pair of columns and larger for another pair.
In the example, the space between the first and the second column is greater than the space between the second and the third.
A second hint is that some rows appear with columns not aligned.
In the example, the header is not aligned with the data.
Tabs are not visible. A file whose field separator is a tab might look like the one in the example.
A first hint that the tab is the separator comes from the fact that the space between the fields varies within the same line:
can be narrower for a pair of columns and larger for another pair.
In the example, the space between the first and the second column is greater than the space between the second and the third.
A second hint is that some rows appear with columns not aligned.
In the example, the header is not aligned with the data.
Show Tabs
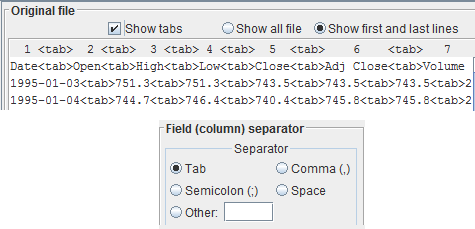 If you have the suspect that the tab is the separator, in order to be sure and to look at tabs clearly, select the checkbox
If you have the suspect that the tab is the separator, in order to be sure and to look at tabs clearly, select the checkbox
Show tabsin the
Original file pane. With the checkbox selected, each tab will be substituted with the string:
<tab>Now you are sure the tab is the separator you are looking for. Select the radio button
Tab
Space
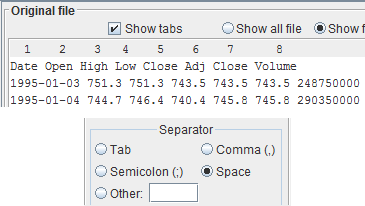 If your file looks like the one in the example, then the separator is a space character (' '). Select the radio button
If your file looks like the one in the example, then the separator is a space character (' '). Select the radio button
Space
Other Characters
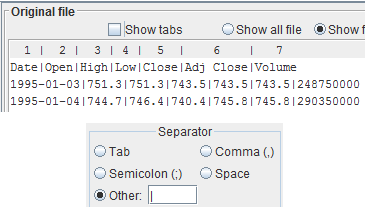 If the field separator for your file is none of the above, you can explicitly set it.
Select the radio button
If the field separator for your file is none of the above, you can explicitly set it.
Select the radio button
Otherand input the character in the adjacent text field. Press the
Enter key on the keyboard after editing this field to make changes effective.
In the depicted example, the field separator is the vertical bar (|), a.k.a. pipe.
Multiple Characters
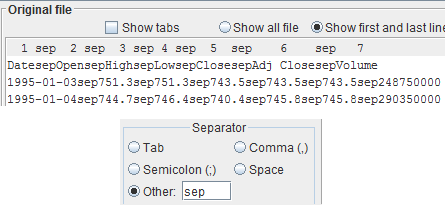 This feature, where you input the field separator in the text field, works even if the separator is not only one character, but a sequence of characters, i.e. a string.
In the example, the field separator is the string, unrealistic, but just to show the capability:
This feature, where you input the field separator in the text field, works even if the separator is not only one character, but a sequence of characters, i.e. a string.
In the example, the field separator is the string, unrealistic, but just to show the capability:
sepYou can enter the string in the text field and it is correctly recognized.
Merge Consecutive Separators
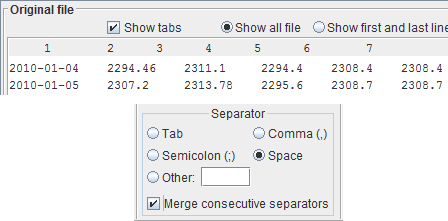 Sometimes there are consecutive separators just to beautify the appearance of the file.
This happens mostly when the field separator is the space.
Multiple spaces might be added between the columns, both in order to align columns and to space columns apart.
In this case, two consecutive spaces could be erroneously interpreted as two real separators with an empty field in between.
In order to clearly distinguish between such cases, if consecutive field separators are added only to make the file more readable, select the checkbox
Sometimes there are consecutive separators just to beautify the appearance of the file.
This happens mostly when the field separator is the space.
Multiple spaces might be added between the columns, both in order to align columns and to space columns apart.
In this case, two consecutive spaces could be erroneously interpreted as two real separators with an empty field in between.
In order to clearly distinguish between such cases, if consecutive field separators are added only to make the file more readable, select the checkbox
Merge consecutive separatorsWhen this checkbox is selected, consecutive separators are considered as one, i.e. they are merged together.
Text Delimiter
Definition
Each single datum between the field separators can be enclosed between two text delimiters so that anything inside is not to be confused with the field separator. Usually, but not necessarily, this happens when the number format has the same character of the field separator. For instance, the thousands separator can be the comma (','); e.g. the number one thousand could be written as:1,000But also the field separator could be the same symbol, the comma. How to distinguish them? By putting numbers between text delimiters, it is specified that their commas are not field separators but number formatting. The field separator is not treated as such when within text delimiters. An example where the text delimiter are the double quotes:
1/1/2000 , 1.2 , "3,400,000"In the third field, the comma is not a field separator but a thousands separator, because it appears between double quotes.
Selecting the Text Delimiter
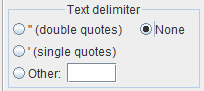 You select the field separator through the dedicated radio buttons.
Almost always the field separator is absent or one of the following characters:
You select the field separator through the dedicated radio buttons.
Almost always the field separator is absent or one of the following characters:
- Double quotes (")
- Single quotes (')
None
Usually, there is no text delimiter, like in all the previous examples. In such cases, select the radio buttonNone
Double Quotes
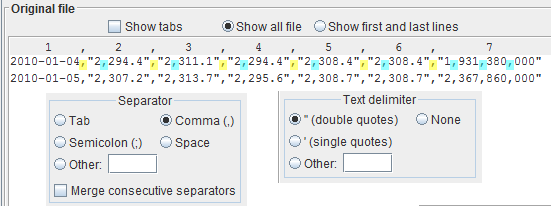 If your file looks like the one in the example, then the text delimiter are the double quotes and the field separator is the comma (','). Select the radio button
If your file looks like the one in the example, then the text delimiter are the double quotes and the field separator is the comma (','). Select the radio button
" (double quotes)Now it is clear when the comma is a thousand separator (light blue) and when it is a field separator (yellow).
Single Quotes
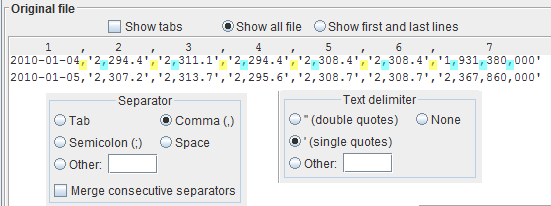 If your file looks like the one in the example, then the text delimiter are the single quotes and the field separator is the comma (','). Select the radio button
If your file looks like the one in the example, then the text delimiter are the single quotes and the field separator is the comma (','). Select the radio button
' (single quotes)Now it is clear when the comma is a thousand separator (light blue) and when it is a field separator (yellow).
Other Characters
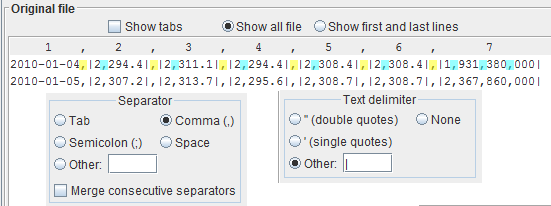 If the text delimiter for your file is none of the above, you can explicitly set it.
Select the radio button
If the text delimiter for your file is none of the above, you can explicitly set it.
Select the radio button
Otherand input the character in the adjacent text field. Press the
Enter key on the keyboard after editing this field to make changes effective.
In the depicted example, the text delimiter is the vertical bar (|), a.k.a. pipe.
Now it is clear when the comma is a thousand separator (light blue) and when it is a field separator (yellow).
Multiple Characters
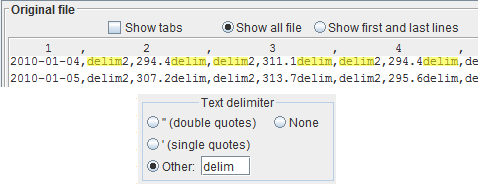 This feature, where you input the text delimiter in the text field, works even if the delimiter is not only one character, but a sequence of characters, i.e. a string.
In the example, the text delimiter is the string, unrealistic, but just to show the capability:
This feature, where you input the text delimiter in the text field, works even if the delimiter is not only one character, but a sequence of characters, i.e. a string.
In the example, the text delimiter is the string, unrealistic, but just to show the capability:
delimYou can enter the string in the text field and it is correctly recognized.
Skip Lines
Lines to Skip
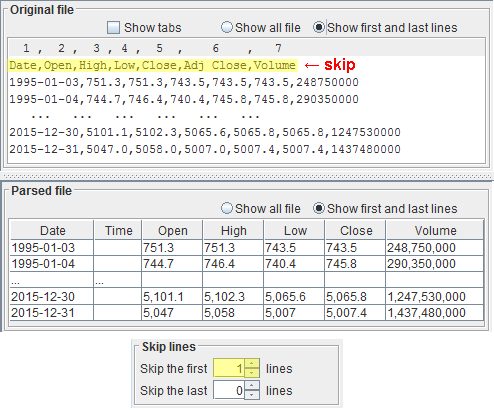 Only lines with data, i.e. the open, high, low, close and volume, must be retained, while the others must be skipped, or ignored.
Typically, an historical file at the beginning has descriptions and a header.
They must all be dismissed.
This might happen, although more rarely, at the end of the file, too.
Empty lines must be dismissed, too and are automatically recognized.
Only lines with data, i.e. the open, high, low, close and volume, must be retained, while the others must be skipped, or ignored.
Typically, an historical file at the beginning has descriptions and a header.
They must all be dismissed.
This might happen, although more rarely, at the end of the file, too.
Empty lines must be dismissed, too and are automatically recognized.
The Skip Lines Spinners
You can select how many lines at the beginning and at the end of the file to skip with the respective spinnersSkip the first lines Skip the last linesFor this task, it is convenient to select the radio buttons
Show first and last linesboth in the
Original file and in the Parsed file panes.
In this example, only the very first line in the file, containing the header, must be skipped.
Fields / Columns
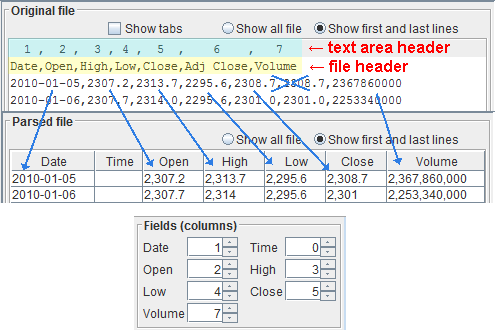 Now we have to identify the fields, or columns, containing the data we are interested in:
Now we have to identify the fields, or columns, containing the data we are interested in:
Date Time Open High Low Close Volume
Look at the File Header First
Once again, the easiest way to do that, is to look at the header. That's exactly what it is there for. Indeed, without the header it wouldn't be obvious what kind of data each column holds. In the example, we have the following file header, highlighted in yellow:Date,Open,High,Low,Close,Adj Close,VolumeFrom the file header we can see that the time is missing, because they are classical end of day data and that there is the adjusted close, which we will dismiss.
The Text Area Header
The text area comes with a very useful header, highlighted in light blue, showing the ordinal number of the field. This way, you can easily locate the field number, because these are the values that you need. This header is relative and aligns to the first line visible in the text area. When you scroll the text area, it will change and adapt accordingly. It is most useful if you scroll the file so that the line with the file header appears first in the text area, so that you have a one-to-one correspondence between a field and its number. Fields start at number 1, not 0.The text area header replicates the field separator, too; comma in the example.
The Spinners
You insert the number of each field through the dedicated spinners. For instance, you insert the number of the close field, or column, in the spinnerCloseand so on.
Missing Field
If a field is missing, like the time in our example, set the spinner to 0.Date
The date field usually contains information like:day / month / yearFor daily data, each entry, or line in the file, is one day. For weekly data, each entry is one week, and the day might not be present. For yearly data, each entry is one year, and the day and month probably are not present. For the date field select the column number of your file containing the indication of the day, month and year, even if one of them is missing. In our example, a classical end of day, the date is the field number 1, so we set the spinner
Date = 1
Time
The time field represents an instant within a day, typically in:hour : minute : secondand is present mostly only for intraday data. Sometimes, the 'second' information is missing. For the time field select the column number of your file containing the indication of the hour, minute and second, even if one of them is missing. In our example, the time is missing, so we set the spinner
Time = 0
Date and Time Together
Sometimes, the information about date and time are condensed in one unique field, like:2017-11-18 09:31:57In such a case you can put it indifferently in the date or time spinner and set the other spinner to 0. For example, if it is the first column, set the spinners like this:
Date = 1 Time = 0
Either the Date or the Time Must Be Present
Either the date or the time must be present. So the following configuration for the spinners is not allowed:Date = 0 Time = 0
Open, High, Low and Close
Proceed the same way, by setting the spinners for open, high, low and close. In our example:Open = 2 High = 3 Low = 4 Close = 5
Adjusted Close
As already explained in another chapter, as in this file there is information about open, high and low, you must use the close, not the adjusted close, in order to have coherent data. Hence, the adjusted close column, number 6 in the example, is simply dismissed.Volume
Select which column contains the volume. In our example, the volume is the field number 7, so we put the spinnerVolume = 7If the volume field doesn't exist, set its spinner to 0.
Warnings and Errors
In order to facilitate you in this task, info, warnings and errors are given by changing the background color and the tooltip of the spinners. Read the tooltip of the spinner signaling that something might be wrong. Don't focus on the single spinner, though, but on the whole picture. Sometimes, a spinner might be set at the right value but signaling a warning just because there is another spinner set to a wrong value. Sometimes the warning or error might be generated by some other controls in the pane having the incorrect value.Other Examples
If the columns in the file are:
1 , 2 , 3 , 4 , 5 , 6 , 7
Date, Time, Open, High, Low, Close, Volume
then select:
Date: 1, Time: 2, Open: 3, High: 4, Low: 5, Close: 6, Volume: 7If the columns in the file are:
1 , 2 , 3 , 4 , 5
Date, Open, High, Low, Close
then select:
Date: 1, Time: 0, Open: 2, High: 3, Low: 4, Close: 5, Volume: 0If the columns in the file are:
1 , 2 , 3
Ticker, Date, Close
then select:
Date: 2, Time: 0, Open: 0, High: 0, Low: 0, Close: 3, Volume: 0or
Date: 2, Time: 0, Open: 3, High: 3, Low: 3, Close: 3, Volume: 0The latter technique about single-valued historical data is explained in the introduction of this section.
Number Format
Numbers are formatted in many different ways, mostly dependent on the language and the country. For instance, the following are different representations of the same number:123,456.7 ← English (United States) 123 456,7 ← French (France) 123.456,7 ← German (Germany)When reading the historical file, Trading Conceiver must parse, or interpret, correctly the numbers.
Two Alternatives
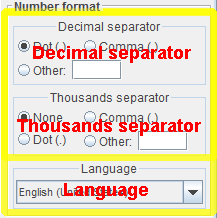 We offer 2 methods to correctly parse the numbers:
We offer 2 methods to correctly parse the numbers:
- By specifying the decimal and thousands separators.
- By selecting the language.
The Original File Text Area Header
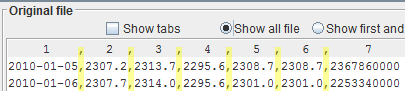 In order to make numbers stand out better, it is useful to select, in the original file pane, the radio button
In order to make numbers stand out better, it is useful to select, in the original file pane, the radio button
Show all fileand scroll the file past the file header and initial descriptions, until you reach the real data. This way, the text area header makes clear where the numbers start and end.
Format for the Parsed File Table
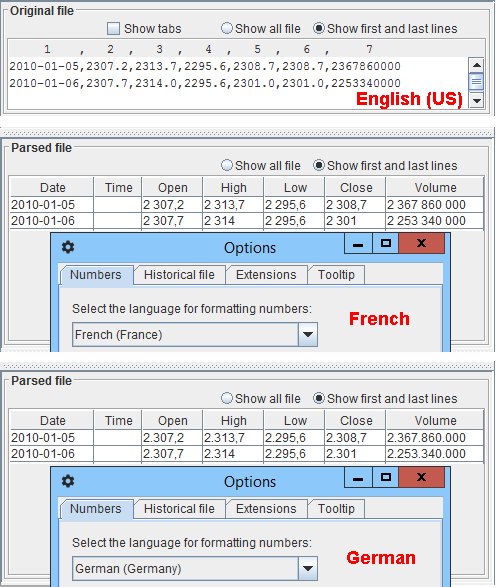 The parsed file table shows the numbers according to the user preference
The parsed file table shows the numbers according to the user preference
Tools → Options → NumbersSo be aware that the numbers in the original file and in the parsed file panes can be formatted in different ways, but they must represent the same numbers. In the example, the original file is in the format
English (US)but the numbers in the parsed file appear as selected in the options preferences, in French or German.
Decimal Separator
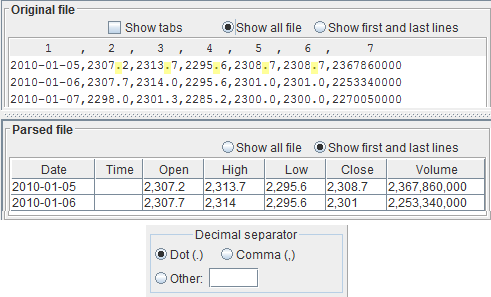 You select the decimal separator through the dedicated radio buttons.
Look at the numbers in the original file text area and select the appropriate decimal separator.
Upon selecting it, make sure the number is interpreted correctly, by looking at the parsed file pane.
The numbers in the original file and in the parsed file panes must correspond.
Almost always the decimal separator is one of the following characters:
You select the decimal separator through the dedicated radio buttons.
Look at the numbers in the original file text area and select the appropriate decimal separator.
Upon selecting it, make sure the number is interpreted correctly, by looking at the parsed file pane.
The numbers in the original file and in the parsed file panes must correspond.
Almost always the decimal separator is one of the following characters:
- Dot (.)
- Comma (,)
123,456.7 ← dot 123 456,7 ← comma 123.456,7 ← comma
Other Characters
If the decimal separator for your file is none of the above, you can explicitly set it. Select the radio buttonOtherand input the character in the adjacent text field. Press the Enter key on the keyboard after editing this field to make changes effective.
Multiple Characters
This feature, where you input the decimal separator in the text field, works even if the separator is not only one character, but a sequence of characters, i.e. a string. You can enter the string in the text field and it is correctly recognized.Thousands Separator
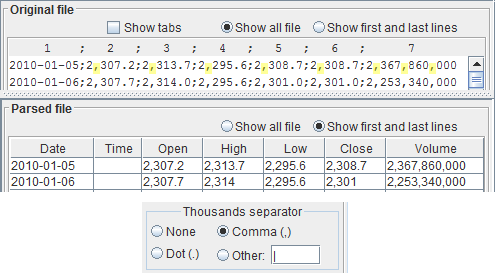 The thousands separator is more appropriately called the grouping separator,
because it can group not only the 'thousands', but also the 'ten-thousands' in some languages.
It is used to enhance readability.
You select the thousands separator through the dedicated radio buttons.
Look at the numbers in the original file text area and select the appropriate thousands separator.
Upon selecting it, make sure the number is interpreted correctly, by looking at the parsed file pane.
The numbers in the original file and in the parsed file panes must correspond.
Almost always the thousands separator either is absent or is one of the following characters:
The thousands separator is more appropriately called the grouping separator,
because it can group not only the 'thousands', but also the 'ten-thousands' in some languages.
It is used to enhance readability.
You select the thousands separator through the dedicated radio buttons.
Look at the numbers in the original file text area and select the appropriate thousands separator.
Upon selecting it, make sure the number is interpreted correctly, by looking at the parsed file pane.
The numbers in the original file and in the parsed file panes must correspond.
Almost always the thousands separator either is absent or is one of the following characters:
- Comma (,)
- Dot (.)
123456.7 ← none 123,456.7 ← comma 123.456,7 ← dot
Other Characters
If the thousands separator for your file is none of the above, you can explicitly set it. Select the radio buttonOtherand input the character in the adjacent text field. Press the Enter key on the keyboard after editing this field to make changes effective. Example:
123 456,7 ← spaceInput a space in the text field. Actually, for instance in the French locale, the space could be not a real space (space bar) but another character, looking like space, but different, like the Unicode character 0xA0 or 0x202F. If you are dealing with a certain language, you are surely familiar with its idiosyncrasies.
Multiple Characters
This feature, where you input the thousands separator in the text field, works even if the separator is not only one character, but a sequence of characters, i.e. a string. You can enter the string in the text field and it is correctly recognized.Language
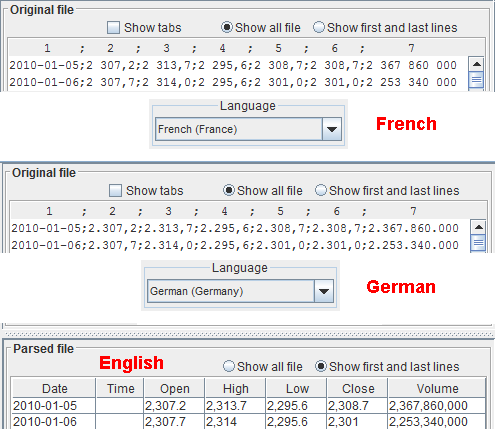 In order to correctly parse numbers, as an alternative to selecting the decimal and thousands separators, you can select the language the numbers are written in.
You select the language through the dedicated combobox.
Note that for the same language there are specific variants linked to countries, like:
In order to correctly parse numbers, as an alternative to selecting the decimal and thousands separators, you can select the language the numbers are written in.
You select the language through the dedicated combobox.
Note that for the same language there are specific variants linked to countries, like:
Spanish (Argentina) Spanish (Mexico) Spanish (Spain) ...Select the appropriate one. Upon selecting it, make sure the number is interpreted correctly, by looking at the parsed file pane. The numbers in the original file and in the parsed file panes must correspond. The examples report an historical file written in French and one written in German. By selecting the right locale, the numbers are interpreted correctly. The parsed file table shows the numbers in English.
Don't Be Deceived by the Language
Don't be deceived by the country you are downloading the historical file from. It does not necessarily match the number format. For instance, an Italian provider could format numbers according to English rules. Look at the numbers.Language: Input and Output
We highlight the fact that theLanguage combobox in this historical file window is used to parse numbers in the input historical file.
On the contrary, the language combobox in
Tools → Options → Numbersis used to format the output numbers throughout Trading Conceiver.
Reverse Order
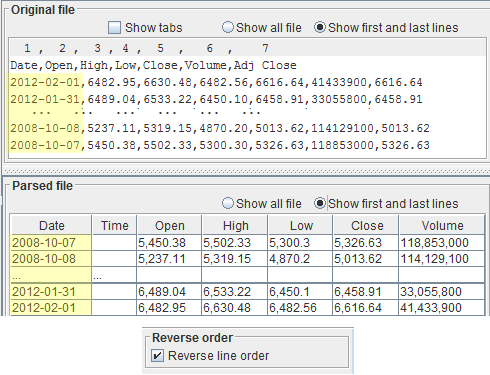 Sometimes the historical file is sorted from the most recent to the least recent date, sometimes the other way around.
In the
Sometimes the historical file is sorted from the most recent to the least recent date, sometimes the other way around.
In the Parsed file table, dates must appear sorted from the oldest (top, first rows) to the most recent (bottom, last rows).
Look at the date / time and make sure it is really that way.
If it's not, you must toggle the checkbox
Reverse line orderBasically, check this box if the most recent date appears first in your file, i.e. if time flows from bottom to top.
Final Steps
The Save Step
 When you are sure the historical file is interpreted correctly, you can press the button
When you are sure the historical file is interpreted correctly, you can press the button
SaveBy saving the current format configuration, you can load it again when needed, without repeating all the previous steps.
The OK Step
 The button
The button
OKis enabled if there are no severe errors and there is a valid license installed. If you are satisfied with how the file has been interpreted, press the 'OK' button. You are now ready to use the file.